







Speech recognition, often referred to as automatic speech recognition (ASR), stands as a remarkable testament to the rapid advancements in the realm of Artificial Intelligence (AI). The journey of speech recognition technology, from its early stages to the current state of AI-powered systems, is a testament to human ingenuity and technological progress. In this digital age, where seamless human-computer interactions are paramount, the evolution of speech recognition has played a pivotal role in shaping how we communicate with machines.
At its core, speech recognition is the process of converting spoken language into written text, enabling computers to understand and interpret human speech. The inception of this technology can be traced back to the mid-20th century when researchers embarked on the ambitious quest to bridge the gap between human communication and computing systems. Initial attempts, such as the pioneering “Audrey” system developed at Bell Labs in the 1950s, laid the foundation for what would become a transformative field.
Over the decades, AI has emerged as the driving force behind the evolution of speech recognition. The adoption of Artificial Intelligence, profound learning techniques, has revolutionized the accuracy and capabilities of speech recognition systems. These advancements have enabled the development of speaker-independent systems that can understand a wide range of accents, dialects, and languages, making speech recognition an integral part of our daily lives.
Today, the fusion of AI and speech recognition has given rise to virtual assistants like Siri, Alexa, and Google Assistant, which have seamlessly integrated into our homes and devices. These AI-powered assistants showcase the potential of speech recognition technology, allowing us to control smart appliances, find information, and even engage in natural conversations with our devices.
In this exploration of the history and development of speech recognition, we will delve into the milestones, breakthroughs, and prospects of this transformative technology. From its early roots to its current role in shaping the AI landscape, the journey of speech recognition is a testament to the boundless possibilities that emerge when human ingenuity converges with artificial intelligence.
Table of Contents
Who introduced speech recognition?
Speech recognition, or automatic speech recognition (ASR), is a field that has evolved over time with contributions from various researchers and institutions. It doesn’t have a single individual or entity credited with its introduction. Instead, it emerged through a series of innovations and breakthroughs by multiple researchers and organizations.
One of the earliest notable attempts at speech recognition was the “Audrey” system developed by Bell Labs in 1952. This system could recognize spoken digits but had limitations in handling complex speech patterns.
In the 1970s and 1980s, researchers began using Hidden Markov Models (HMMs) to model speech signals, marking a significant advancement in the field. This statistical approach allowed for improved accuracy in recognizing spoken words.
Over time, various research institutions and companies, including IBM, Carnegie Mellon University, and Dragon Systems (later acquired by Nuance Communications), played significant roles in advancing speech recognition technology.
The introduction and development of speech recognition technology have been a collaborative effort involving numerous scientists, engineers, and organizations. It has evolved from early experimental systems to the sophisticated AI-powered systems we have today, with continual contributions from researchers worldwide. Speech recognition has become an integral part of our digital lives, enabling voice assistants, transcription services, and more, thanks to the collective efforts of many innovators in the field.

What is the overview of speech recognition?
Speech recognition, also known as Automatic Speech Recognition (ASR), is a technology that enables computers to understand and interpret spoken language. It is a subfield of artificial intelligence (AI) and natural language processing (NLP) that has witnessed significant advancements in recent years. Here is an overview of speech recognition:
Speech Input
Speech recognition systems take audio input, typically in the form of spoken words or phrases, and convert it into written text. This input can come from a variety of sources, including microphones, telephone lines, or recorded audio.
Acoustic and Language Models
Speech recognition relies on two key components: acoustic models and language models. Acoustic models analyze the sound patterns in speech, while language models interpret the linguistic context and grammar of spoken words.
Deep Learning
Recent advancements in deep learning, particularly deep neural networks (DNNs), have revolutionized speech recognition. These neural networks can learn complex patterns in speech data, leading to improved accuracy and robustness in recognizing spoken words.
Applications
Speech recognition has a wide range of applications. It is used in voice assistants (e.g., Siri, Alexa), transcription services, customer service chatbots, automated telephone systems (IVR), and more. It has also found applications in healthcare (medical dictation), automotive (voice-controlled infotainment systems), and accessibility (for individuals with disabilities).
Challenges
Despite its advancements, speech recognition faces challenges related to accents, dialects, background noise, and varying speaking styles. Achieving high accuracy across diverse linguistic contexts remains a research focus.
Future Prospects
The future of speech recognition holds promise for even greater accuracy, multilingual support, and integration with other AI technologies like natural language understanding and computer vision. As AI continues to advance, speech recognition will play a crucial role in enabling more natural and intuitive interactions between humans and machines.
What is the history of the speech recognition system?
Speech recognition, also known as automatic speech recognition (ASR), is a technology that enables computers to understand and interpret human speech. The history of speech recognition dates back several decades, with significant advancements made in the field. Here is a brief history of speech recognition:
Early Attempts (1950s-1960s)
The origins of speech recognition technology can be traced back to the mid-20th century, particularly the 1950s and 1960s, when computer scientists and engineers first embarked on the groundbreaking journey of enabling machines to recognize and comprehend human speech. These early years marked the initial forays into a field that would later become a cornerstone of artificial intelligence and human-computer interaction.
During this period, researchers faced formidable challenges due to the complexity of human language and the limitations of computing power. One notable milestone in the history of speech recognition was the development of the “Audrey” system by Bell Labs in 1952. Audrey was a pioneering achievement, capable of recognizing spoken digits, albeit with limited capabilities compared to contemporary systems. It laid the foundational groundwork for subsequent research in the field.
Despite its modest beginnings, the development of Audrey and similar early systems marked the beginning of a quest to bridge the gap between human communication and computing machines. Over the ensuing decades, advances in technology, linguistic research, and the advent of artificial intelligence would propel speech recognition to remarkable heights, revolutionizing industries and transforming the way humans interact with computers and devices.
Hidden Markov Models (1970s-1980s)
In the 1970s and 1980s, the integration of Hidden Markov Models (HMMs) into speech recognition marked a pivotal turning point in the field’s development. HMMs brought a transformative methodology that harnessed statistical modeling to capture the intricacies of spoken language.
HMMs are a mathematical framework that excels at modeling sequences of data, making them ideal for speech recognition tasks. In the context of speech, HMMs allow researchers to represent the statistical properties of speech signals, including phonemes, words, and even entire sentences. This statistical modeling approach greatly enhances the accuracy of speech recognition systems.
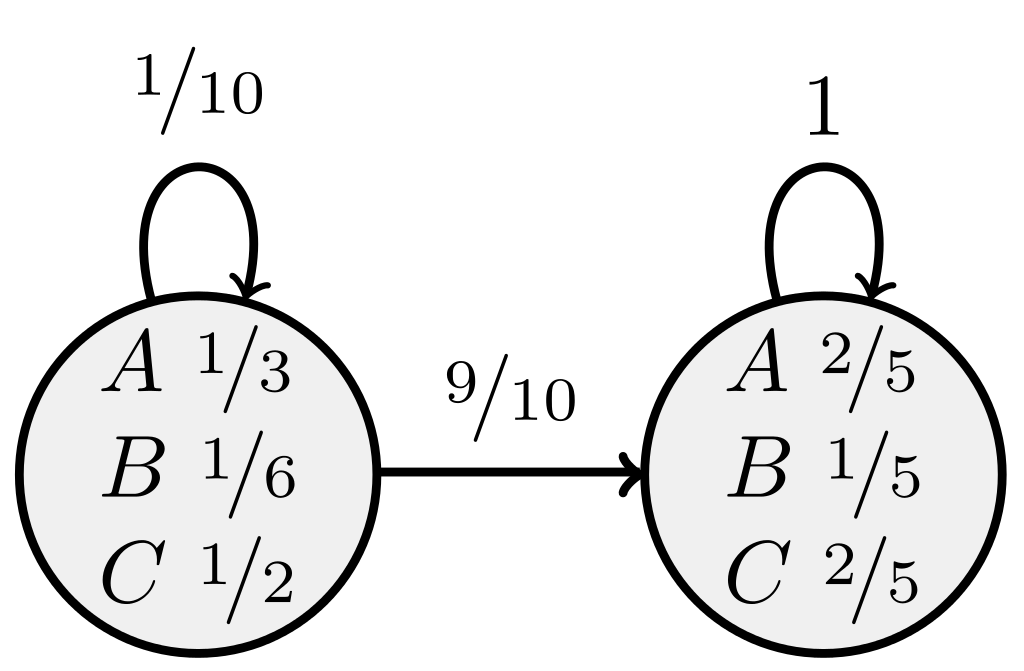
The key innovation was HMMs’ ability to handle variability in speech. They could account for the fact that different speakers may pronounce words differently and that the same word might sound distinct depending on the surrounding words. By modeling these variations probabilistically, HMMs made it possible to create more robust and adaptable speech recognition systems.
As a result of HMM’s incorporation, speech recognition technology began to transition from experimental systems limited to a narrow set of controlled conditions to more practical and versatile applications. This laid the foundation for the subsequent decades of progress in the field, ultimately culminating in the advanced speech recognition systems we use today, powered by deep learning and artificial intelligence.
Introduction of Speaker-Independent Systems (1980s)
Before the 1980s, speech recognition technology was primarily constrained by the need for speaker-dependent systems. These early systems required extensive training on a specific user’s voice patterns, making them impractical for widespread use. Users had to invest time and effort to adapt the system to their unique speech characteristics, limiting the technology’s accessibility and usability.
The breakthrough came in the 1980s with the emergence of speaker-independent systems. These systems were designed to recognize and understand the speech of various speakers without the need for extensive individualized training. Instead of relying on specific voice profiles, speaker-independent systems utilized statistical models and linguistic knowledge to decipher spoken language, making them far more versatile and user-friendly.
This shift toward speaker-independence marked a significant milestone in the development of speech recognition technology. It paved the way for the integration of speech recognition into a broader range of applications and eliminated the need for users to invest substantial time in training the system. As a result, speech recognition became more accessible and practical, setting the stage for its subsequent advancements and widespread adoption in various fields and industries.
Large Vocabulary Systems (1990s)
The 1990s represented a pivotal era in the history of speech recognition, characterized by the development of large vocabulary continuous speech recognition (LVCSR) systems. This period marked a substantial leap forward in terms of both accuracy and usability, ushering in a new era of practical applications for speech recognition technology.
One of the key achievements of the 1990s was the ability of LVCSR systems to handle more extensive vocabularies. Previous systems had limitations in terms of the number of words or phrases they could recognize effectively. LVCSR systems, however, could handle a much broader range of vocabulary, making them suitable for various real-world applications.
One of the most notable applications was dictation software. The improved accuracy of LVCSR systems made them increasingly valuable for professionals, such as medical practitioners, lawyers, and journalists, who relied on transcription services. These systems allowed users to dictate their spoken words, which were then transcribed into written text with impressive precision.
Overall, the 1990s represented a turning point in the evolution of speech recognition technology, bringing it closer to the mainstream and demonstrating its practical utility in a wide range of fields. This era laid the foundation for the continued development and integration of speech recognition into various aspects of our daily lives in subsequent decades.
Commercial Applications (1990s-2000s)
In the late 1990s and early 2000s, speech recognition technology experienced a significant transformation as it transitioned from research laboratories into mainstream commercial applications. This pivotal period marked a turning point in the adoption of speech recognition across various industries. Two prominent companies, IBM and Nuance Communications, were instrumental in driving this expansion.
IBM, a technology powerhouse with a rich history in innovation, made substantial contributions to speech recognition during this era. Their efforts in developing and refining speech recognition systems, such as the IBM ViaVoice software, allowed for practical applications in businesses and consumer electronics. IBM’s involvement helped establish speech recognition as a viable tool for enhancing customer service, automating tasks, and improving accessibility.
Nuance Communications, a company specializing in speech and imaging solutions, played a pivotal role in advancing speech recognition for commercial use. They developed cutting-edge speech recognition technologies and software, making it easier for businesses to integrate speech interfaces into their products and services. Nuance’s Dragon NaturallySpeaking software, for instance, enabled accurate dictation and voice command capabilities for personal computers.
The adoption of speech recognition in automated telephone systems (Interactive Voice Response or IVR) streamlined customer service interactions, reducing the need for human operators and improving efficiency. In consumer electronics, voice commands have become increasingly popular, allowing users to control devices, search the internet, and perform various tasks using voice input. These developments reshaped the way we interact with technology and paved the way for the voice-controlled world we live in today.
Rise of Deep Learning (2010s-Present)
The 2010s marked a pivotal era in the history of speech recognition, driven by the widespread adoption of deep learning techniques, notably deep neural networks (DNNs). This paradigm shift transformed the field by dramatically enhancing the accuracy and capabilities of Automatic Speech Recognition (ASR) systems.
Deep neural networks are computational models inspired by the structure and function of the human brain, consisting of multiple layers of interconnected nodes or neurons. These networks excel at learning intricate patterns and representations from vast amounts of data, making them ideally suited for speech recognition tasks.
One of the key drivers of this breakthrough was the availability of large-scale datasets and advancements in computing power. The abundance of audio data, transcribed speech, and linguistic resources allowed researchers to train DNN-based ASR models on massive datasets, enabling them to capture nuances in pronunciation, accents, and speaking styles.
Additionally, the evolution of Graphics Processing Units (GPUs) and specialized hardware accelerators provided the computational muscle needed to train and deploy deep learning models efficiently. This synergy of data, algorithms, and computing power propelled ASR systems to unprecedented levels of accuracy and robustness.

As a result, speech recognition has not only become a fundamental component of virtual assistants and voice-activated devices but has also found applications in healthcare, finance, customer service, and more. The 2010s, therefore, represent a transformative period in speech recognition, laying the foundation for the continued advancement of this technology into the future.
Integration into Everyday Devices
With the rise of virtual assistants like Apple’s Siri, Amazon’s Alexa, Google Assistant, and Microsoft’s Cortana, speech recognition has transcended its niche status and has become an integral part of everyday technology. These virtual assistants represent a paradigm shift in human-computer interaction by offering users the ability to engage with their devices and access information using natural language speech commands.
These virtual assistants are designed to understand and respond to spoken words and phrases, making tasks such as setting reminders, sending messages, checking the weather, or even controlling smart home devices as simple as uttering a sentence. This convenience has not only transformed the way we interact with our devices but has also made technology more accessible to individuals with varying levels of technical expertise.
Moreover, these virtual assistants have spurred innovation in other areas as well. They have catalyzed the development of voice-activated smart speakers and IoT (Internet of Things) devices, creating a connected ecosystem where speech recognition is the primary mode of interaction. As speech recognition technology continues to advance, we can anticipate even more seamless and intuitive interactions with our digital environments, further blurring the lines between humans and machines in our daily lives.
Ongoing Advancements (Present)
Speech recognition technology has made remarkable strides in recent years, offering a remarkable level of versatility and accuracy. One of its notable achievements is its ability to recognize a vast array of accents, languages, and dialects. This inclusivity has globalized the technology, making it accessible and useful to people from diverse linguistic backgrounds.
In terms of applications, the uses of speech recognition are incredibly diverse. Transcription services have benefited tremendously, streamlining the process of converting spoken words into text, which is particularly valuable in fields like journalism, legal documentation, and healthcare. Voice-controlled smart devices have become ubiquitous in modern households, allowing users to control lights, thermostats, and other appliances with simple voice commands. Additionally, customer service chatbots, powered by speech recognition, provide efficient and convenient support, enhancing customer experiences across various industries.
As speech recognition technology continues to evolve, it holds the potential to break down language barriers further, improve accessibility for individuals with disabilities, and find innovative applications in fields such as education, entertainment, and healthcare. Its adaptability and growing integration into everyday life make it a cornerstone of AI-driven interactions in our increasingly interconnected world.
Multimodal Approaches (Future)
Looking ahead, the future of speech recognition holds exciting possibilities as it converges with other modalities and technologies. One of the key directions is the integration of speech recognition with natural language understanding (NLU). This combination will enable systems not only to transcribe spoken words but also to comprehend the meaning, intent, and nuances behind them. Imagine a virtual assistant that not only listens to your voice commands but also understands the context and can engage in more natural and meaningful conversations.
Furthermore, the synergy between speech recognition and computer vision is poised to revolutionize how we interact with the world. Integrating speech with visual information can enable applications like augmented reality (AR) and smart glasses to provide users with real-time, context-aware information. For instance, you could simply ask your glasses for directions, and they would not only understand your request but also overlay visual cues on your field of view.
Contextual information, including user history and environmental data, will play a pivotal role in enhancing speech recognition. Systems will become more adaptive, capable of anticipating user needs and providing proactive assistance.
The future of speech recognition is about breaking down the barriers between human communication and technology. By seamlessly integrating speech recognition with other modalities and leveraging contextual information, we are moving closer to creating intelligent, context-aware systems that enhance our daily lives and interactions.
The evolution of speech recognition technology represents a remarkable journey that reflects the relentless pursuit of bridging the gap between human communication and machines. What began as rudimentary experimental systems in the mid-20th century has evolved into a sophisticated and integral component of our modern technological landscape. The trajectory of speech recognition has been characterized by steady progress and groundbreaking technological advancements.
From the early days of “Audrey” to the present era of AI-powered voice assistants like Siri, Alexa, and Google Assistant, speech recognition has undergone a transformative evolution. The integration of Artificial Intelligence (AI), particularly deep learning techniques, has revolutionized its accuracy and capabilities, enabling it to understand diverse accents, languages, and dialects.
Today, speech recognition has transcended its origins and found applications in diverse fields, including healthcare, customer service, automotive technology, and accessibility. Its future promises even more exciting possibilities as it continues to merge with other AI technologies like natural language understanding and computer vision, ultimately reshaping how we interact with computers and devices. As the journey of speech recognition unfolds, it reaffirms the inexhaustible potential of human innovation and technological progress.





