







Imagine trying to find a specific file on the internet in the late 1980s. There was no Google, no Bing, not even a Yahoo. The internet was a much smaller, unorganized frontier known to only a few, and finding information felt like searching for a needle in a digital haystack. It was during this pre-Google internet era that a groundbreaking tool named Archie emerged.
Archie is widely recognized as the first internet search engine – a humble yet revolutionary system that changed how we discover information online. This blog post dives into the history of the Archie search engine, from its origins and technology to its creator Alan Emtage’s motivations, and explores how this early search engine compares to modern giants like Google. We’ll also look at why Archie eventually declined, what came after, and the legacy it left in the evolution of search engines.
Table of Contents
The Early Internet: Life Before Search Engines
To appreciate Archie’s importance, we need to understand what the internet looked like in the late 1980s and early 1990s. This was the era of the pre-Web, pre-Google internet, when the World Wide Web was still in its infancy (Tim Berners-Lee introduced the web around 1991, but it had yet to spread). Back then, most online activity was text-based and command-line driven. There were no browsers with Google search boxes — users navigated using tools like FTP and Gopher, or read discussions on Usenet forums.
One of the primary ways to share and obtain files (like software, documents, or datasets) was through FTP (File Transfer Protocol) servers. These were publicly accessible directories where universities, research institutions, and hobbyists stored files for download. However, there was a big problem: finding something on the internet meant you had to know exactly where to look. If you needed a specific software program or paper, you might have to manually connect to dozens of FTP servers one by one, list their files, and hunt through directories until you (hopefully) found the file you wanted. There was no central index or search function to tell you which server held the file.
This made the early internet a bit like a giant unorganized library without a catalog. People relied on word of mouth, emailed newsletters, or published “internet directories” to learn where to find things. It was tedious and frustrating. For example, an academic looking for a particular piece of public-domain software might spend hours combing through different university FTP archives. The need for a better way to locate files was obvious, even as the internet community and the volume of data were rapidly growing. Enter Archie – the tool that would transform this chaotic file-finding process.
Alan Emtage: The Creator of the First Internet Search Engine
Every great invention has an innovator behind it. In Archie’s case, that was Alan Emtage, a computer science graduate student at McGill University in Montreal, Canada. Alan Emtage’s journey to creating the first search engine is a fascinating story of necessity and ingenuity.
Alan Emtage was born and raised in Barbados, and he moved to Canada to attend McGill in the 1980s. By 1989, he was working in McGill’s IT department as a systems administrator while pursuing his studies. Part of his job was helping professors and students find software tools and resources on the internet. This essentially meant he became a human search engine — manually scouring the scattered FTP archives on the nascent internet to locate files upon request.

As you can imagine, this task was cumbersome and time-consuming. Emtage has humorously admitted that he considered himself “lazy” in the sense that he didn’t want to keep doing repetitive manual searches for files. Like any clever programmer, he sought to automate a tedious task.
In 1989, Alan Emtage decided to write a program to do the searching for him. Working with colleagues (including Bill Heelan and J. Peter Deutsch), he developed a script that could connect to multiple FTP sites, fetch directory listings of files, and aggregate them into a searchable database. This pet project soon evolved into Archie – a tool that could index file names from all over the internet and tell you where a desired file was located.
The name “Archie” comes from the word “archive” (without the “v”), reflecting its purpose of archiving index information. (Contrary to a popular myth, it wasn’t named after the Archie comic character, though this coincidence later inspired other services named Jughead and Veronica after Archie’s comic pals.)
Archie officially went live in 1990, when Alan Emtage was still a postgraduate student. With this innovation, Emtage effectively created the world’s first internet search engine (even if the term “search engine” wasn’t in use yet). Notably, Emtage did not patent the Archie technology or his search algorithms. At the time, the internet wasn’t viewed as a commercial space – it was a cooperative academic network – so he freely shared Archie as a helpful tool, making no money from it.
In later interviews he joked that he “didn’t make any money off it, but wouldn’t change a thing,” proud that he solved a problem for the community.In 2017, Alan Emtage was inducted into the Internet Hall of Fame for his pioneering work. His contribution is often overshadowed by later search giants, but Emtage’s creation of Archie laid the foundation for everything that followed.
How Archie Worked: FTP Indexing in a Pre-Web Era
So, how did the Archie search engine actually work? In concept, Archie was simple yet brilliant. It performed FTP indexing – essentially, it compiled a centralized database of filenames from countless public FTP servers on the internet, so that users could search that database instead of manually trawling through sites.
Here’s a closer look at Archie’s inner workings and how people used it in the early ’90s:
- Crawling FTP Servers: Archie’s software would periodically connect to a list of known anonymous FTP sites around the world. It used automated scripts (originally via Telnet, a remote login protocol) to retrieve directory listings of each server’s files and folders. Think of this like a web crawler, except it was crawling file servers instead of web pages. Because bandwidth and computing power were limited, Archie didn’t scan continuously; it typically updated its index about once a month for each server. This was enough to keep track of new additions without overloading the network or the host servers.
- Building the Index: The data Archie gathered – basically long lists of filenames and their locations – was merged into a master index (a searchable database). In practice, the Archie team stored these listings in text files and used a Unix tool (the
grepcommand) to search through them. The index was massive for its time: at its peak Archie indexed millions of files (around 2 million or more) from over a thousand FTP repositories worldwide. This was essentially the entire known internet of downloadable files in the early ’90s. - User Queries via Command Line: Unlike today’s slick web search boxes, using Archie required a bit of technical know-how. There was no web interface initially (the Web itself was brand new and not widely used yet). Instead, users accessed Archie through a few different methods:
- Interactive Login (Telnet): A user could telnet (open a text-based remote connection) to an Archie server (for example,
archie.mcgill.ca) and enter search commands directly. At the Archie prompt, you would type a search query (usually a keyword or pattern that might be in the filename you want). Archie would then search its index for matching filenames and output a list of results on the screen. - Archie Client Programs: As Archie grew popular, dedicated client software emerged. For instance, a command-line tool called “archie” was created for various operating systems, and a graphical client called “xarchie” was available for computers with X Window (Unix graphical interface). These programs let you send a query to an Archie server and get results, without manually logging in via Telnet each time.
- Email Queries: In an age when many users had email but not full internet access, Archie even allowed searches via email. You could send an email to a special Archie email address with your query in the message body, and the server would reply with the search results. This sounds archaic now, but it was a handy trick for those early users who lived in an email-only world.
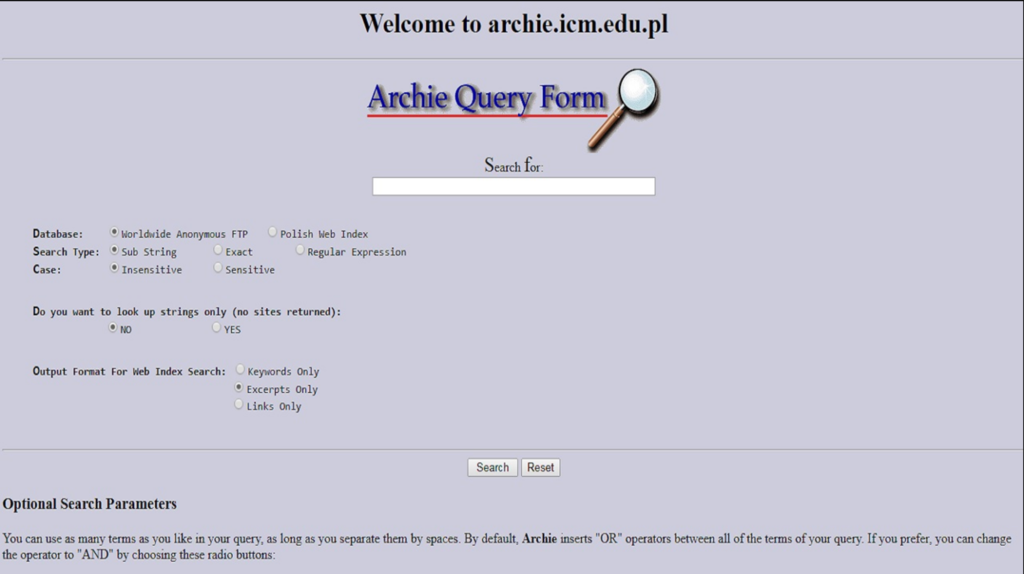
- Later Web Interface: Eventually, once the World Wide Web gained traction a few years later, some Archie servers provided a basic web form for queries. By the mid-90s you could find websites (like the “Archie Query Form”) where you could enter a search term and see Archie results on a webpage. However, by the time the web interface existed, Archie was already past its heyday.
- Interactive Login (Telnet): A user could telnet (open a text-based remote connection) to an Archie server (for example,
- Interpreting Search Results: When Archie found matches for a query, it would display the filenames along with the server where each file was located (and sometimes the directory path or file size). For example, if you searched for a file named “chess,” Archie might list several files like
chess.tar.gzonftp.cs.someuniversity.edu(in the/pub/gamesdirectory) and other similar hits. It was then up to you to take that information and actually retrieve the file using FTP. In other words, Archie didn’t download files for you or provide clickable links — it simply told you where on the internet the file existed. This was still a huge leap forward in convenience. Instead of blind hunting, you got a roadmap to the content you wanted. - Limitations: By design, Archie only indexed filenames (and perhaps some brief descriptions, if available); it did not index the contents of files. So you had to search based on what a file was named, not what was inside it. Archie also didn’t understand natural language or questions — you couldn’t ask “what’s the weather” or “how do I program in C?” and get answers. You had to think in terms of keywords likely to be in the file names. If you weren’t sure exactly what the file might be named, you often tried multiple searches with wildcards. Additionally, Archie’s results weren’t ranked by relevance; they were usually listed alphabetically or by server. Despite these constraints, in the early ’90s Archie was a godsend for netizens.
Archie quickly became an indispensable tool for researchers, students, and software developers looking for resources online. In fact, it became a victim of its own popularity — the main Archie server at McGill University was bombarded by queries from around the world. At one point, Archie searches reportedly made up over half of the total internet traffic in Canada! To relieve the load, the Archie team set up multiple mirror servers across different countries (about 30 servers worldwide) that synchronized the index and handled searches for their regions. This distribution was an early example of scaling an internet service, much like how modern content is served from multiple data centers.
Why Archie Mattered: A Revolution in Information Retrieval
Archie might sound primitive by today’s standards, but in the context of the early ’90s it was nothing short of revolutionary. It fundamentally changed the way people interacted with the internet by proving that you could search the network’s information instead of just browse or stumble across it.
Before Archie, finding a file or piece of information on the internet was often a manual slog or a lucky guess. After Archie, users could locate what they needed in seconds by typing a simple query. This leap in efficiency is hard to overstate — imagine going from flipping through a phone book page by page to suddenly having a “find” function that pinpoints exactly what you need.
Archie brought a sense of order to the chaos of early internet files. It democratized access to online resources: a student in one country could easily discover and download software from a server in another country, something that would have been nearly impossible before. By breaking down barriers to information, Archie helped accelerate collaboration and knowledge sharing among the internet’s first users.
Importantly, Archie introduced the very idea that we now take for granted: that an automated system could index and retrieve information across a global network. This concept is the bedrock of all modern search engines. Many of the techniques that Google and others later expanded upon — like crawling remote servers, building a searchable index, and querying it with keywords — were demonstrated in a basic form by Archie. In that sense, Archie was the proof-of-concept for internet search. It showed that as the internet grew, such tools would be essential to tame the exponential increase in information.
Archie’s immediate success also inspired a wave of successors and parallel projects. Its core idea was applied to other network systems as they emerged. For example, when the Gopher protocol (a menu-driven information system) became popular around 1991, there was soon a need to search Gopher content. Thus came Veronica (in 1992), a search engine for Gopher sites that essentially did for Gopher what Archie did for FTP.
Within the realm of FTP search, others tried building on Archie’s concept as well. It’s telling that one of the first search tools for the World Wide Web was called ALIWEB (in 1993), which stood for “Archie Like Indexing for the Web” — an explicit nod to Archie’s influence, aiming to do something similar for the blossoming web.

In short, Archie’s debut marked the dawn of a new era. It solved an immediate problem for the early internet community, and in doing so it changed everyone’s expectations of what was possible. After Archie, the idea that you should be able to quickly find what you want online started to take hold — an expectation that only grew as the internet exploded in size. This set the stage for the more sophisticated search engines that were soon to come.
Archie vs. Modern Search Engines: From FTP Files to Google’s AI
To truly appreciate how far search technology has come, it’s worth comparing Archie with a modern search engine like Google. The differences highlight just how much innovation occurred in the years after Archie:
- What’s Indexed: Archie indexed the names of files on FTP servers. Modern search engines index almost everything – the full text of web pages, documents, images, videos, and more. Google’s crawlers visit webpages and read them in their entirety, so you can search for words that appear anywhere on a page (not just in the title or filename). Archie’s scope was tiny compared to the vast ocean of information that Google combs through.
- Depth of Understanding: Archie had zero understanding of content or context; it was a straightforward database of filenames. Today’s search engines use sophisticated algorithms and AI to understand context, correct spelling, and even interpret natural language queries. For example, Google can take a question like “What’s the weather today?” and know you’re likely looking for a local forecast, not a file literally named “weather today.” Archie could never do that — it would only match the exact words “weather” or “today” in a filename, which wasn’t very useful for answering questions.
- User Interface and Ease of Use: Using Archie often meant dealing with a text-only interface and remembering arcane commands. In contrast, modern search engines have intuitive interfaces accessible to anyone with an internet connection. You go to a website (or open an app), type or speak your query in plain language, and get instant results with clickable links, images, and rich information. The barrier to entry is essentially zero now. In Archie’s era, you had to be something of a computer geek to even get online and run a search.
- Ranking and Relevance: Archie did not rank results in any intelligent way — a search for “chess” might give you a dozen file names in alphabetical order, regardless of which file was most relevant or popular. Modern engines like Google use complex ranking algorithms (like Google’s famous PageRank, among hundreds of other factors) to determine which results best answer your query, and they show those first. This focus on relevance means that a Google user typically finds what they need in the first one or two hits, whereas an Archie user might have had to sift through a long list of matches and decide manually which file seemed like the one they wanted.
- Scale and Speed: Archie’s index at its height was a few million entries, and updates were infrequent (monthly for each site). Google indexes tens of billions of webpages and is constantly updating, with web crawlers working 24/7 to add new content and refresh old pages. Yet a Google search usually takes less than a second to run, thanks to massive data centers and advanced optimizations. Archie’s searches, running on much more modest servers of the early ’90s, could take a few seconds to return results and might slow down if a lot of people searched at once. By modern standards it was slow and limited, but at the time, Archie’s ability to query a worldwide database in seconds felt incredibly fast.
- Features and Specialization: Modern search engines offer many features beyond just finding a webpage — they can show you maps, translate languages, answer questions directly (with “featured snippets”), suggest related searches, and so on. There are also specialized search engines for images, academic papers, products, and more. Archie was a one-trick pony: it found filenames, and that was it. It didn’t integrate with other tools or have different verticals of search. Today’s search ecosystem is far more rich and diverse.
Despite these dramatic differences, you can draw a line from Archie to Google in terms of the core mission: helping users find what they need on the internet. Google’s corporate mission statement, “to organize the world’s information and make it universally accessible and useful,” echoes what Archie did on a much smaller scale for the early internet. Google just has the benefit of advanced technology, enormous computational power, and decades of intervening progress. Archie was the proof-of-concept that showed such “information organization” was both possible and invaluable.
The Decline of Archie and the Rise of New Search Tools
Given how quickly the internet grew and changed in the 1990s, it’s not surprising that Archie’s dominance was short-lived. Here’s what happened as the search landscape evolved and why Archie eventually faded away:
- The Web Takes Over: In the early 90s, the internet experienced a major shift with the advent of the World Wide Web. By 1993 and 1994, more people were creating and visiting websites (hosted over HTTP) rather than relying solely on FTP or Gopher. Archie was built for FTP file search and wasn’t indexing web pages. As the web’s popularity exploded, the need arose for tools that could search web content. The first solutions included things like ALIWEB (1993), which, as mentioned, stood for “Archie-Like Indexing for the Web” – it allowed website owners to submit their pages for indexing. Soon after, fully automated web crawlers appeared: WebCrawler (1994) could index entire pages’ text, and Lycos (1994) quickly expanded to catalog a large portion of the web. Compared to these, Archie’s focus on filenames felt increasingly narrow. The center of gravity for finding information was moving to web search, leaving Archie somewhat stuck in the past.
- Gopher’s Moment and Veronica: For a brief time in the early 90s, the Gopher protocol was a popular way to share documents on the net. Archie didn’t handle Gopher, so Veronica (released in 1992) stepped in to provide search across Gopher’s menu listings. Veronica (jokingly named as an acronym for “Very Easy Rodent-Oriented Net-wide Index to Computerized Archives”) performed a similar role for Gopher as Archie did for FTP. There was also Jughead, which could search within a single Gopher server’s index. While Gopher itself was soon overshadowed by the web, the rise of Veronica and Jughead in 1992-93 meant that for many users, Archie wasn’t the only search game in town. If you were primarily looking for information on Gopher, you’d use Veronica instead of Archie. In short, the expansion of different internet systems meant that search became decentralized — FTP had Archie, Gopher had Veronica/Jughead, and the web would soon have its own set of search engines.
- Yahoo! and the Directory Era: An alternative approach to finding things online gained prominence around 1994 with the rise of Yahoo! Instead of algorithmic search, Yahoo started as a curated directory of websites organized by categories. You could browse topics to find sites, which was a very different user experience compared to typing keywords. For newcomers to the web, directories like Yahoo (and others such as LookSmart or the Open Directory Project) were a friendly way to discover popular sites without knowing any search syntax. While Yahoo eventually incorporated search, its early success as a directory reflected a pivot in how people found information — through portal sites and human-curated recommendations. Archie, being a low-profile utility for techies, didn’t have that mass-market appeal or a glossy interface; it remained a tool mainly for those who knew exactly what they were looking for (specific files). As internet use expanded to less technical users, tools like Yahoo captured the public’s attention in a way Archie never did.
- A Flood of New Search Engines: By the mid to late ’90s, dozens of search engines and discovery tools sprang up to help people navigate the web. AltaVista launched in 1995 and was a game-changer, offering fast, comprehensive full-text searches of a huge chunk of the web and even allowing natural language queries. Excite, Infoseek, HotBot, Ask Jeeves, and many more each had unique features and indexed web content rather than just file names. These search engines were heavily advertised, competed with each other, and became the starting points for many web surfers. In this storm of innovation, Archie – which still essentially indexed only FTP sites – became less and less relevant. The number of FTP servers didn’t grow anywhere near as fast as the web itself, and many files formerly available via FTP were getting hosted on web pages or new platforms. Essentially, the world moved on, and Archie stayed in its niche.
- The Google Era and Beyond: The final step in this evolution was the emergence of Google in 1998. Google’s superior technology (like PageRank-based ranking and a clean, simple interface) quickly made it the dominant search engine, eclipsing the earlier generation of 90s search services. By the early 2000s, Google was the undisputed king of search, and the notion of going to a separate tool to find FTP files was antiquated. Even FTP itself was used less by regular users (who gravitated to HTTP and later to peer-to-peer file sharing or other methods for downloads). Archie’s maintainers eventually ceased updating it; work on the project largely stopped in the late 90s. Alan Emtage’s company, Bunyip Information Systems, which had been founded to commercialize Archie, closed down in 2003. By then, Archie was practically a historical artifact – fondly remembered by some, but no longer in active use.
In summary, Archie declined because the internet outgrew it. What started as the first solution to internet search evolved into a diverse ecosystem of search tools specialized for new types of content. Archie’s FTP-only focus couldn’t keep up with the web’s rise, and its text-based interface didn’t translate to the increasingly user-friendly, graphically-driven internet of the late 90s. It served its purpose brilliantly for a few years, and then those needs were met by next-generation tools.
Archie’s Legacy in Internet History
Although Archie itself is long retired, its legacy lives on as an integral chapter in the story of the internet. In retrospect, we can clearly see how Archie influenced and foretold the development of search technology:
The First to Tame the Internet: Archie proved that the scattered information on the internet could be collected, organized, and searched. It was the first tool to show that searchability is crucial for a usable internet. This principle – that users should be able to find what they need quickly – has driven internet innovation ever since. Every search bar on every website, every query-able database online, traces a lineage back to the idea that Alan Emtage implemented with Archie.
Inspiring Other Innovators: Many who built subsequent search engines were aware of Archie. The creators of Veronica and other early 90s tools explicitly mirrored the Archie model in their domains. Even when Martijn Koster introduced ALIWEB for the web, he positioned it as an “Archie for the Web,” acknowledging that Archie set the template. The very term “search engine” became part of our lexicon thanks to these early tools; it’s now easy to forget that someone had to invent the concept. Archie’s success made it obvious to a generation of developers and entrepreneurs that search engines were not just possible but essential.
Recognition of Alan Emtage: For a long time, Alan Emtage didn’t have the same public profile as tech figures like Bill Gates or Steve Jobs, largely because he created Archie in an academic setting and never became a billionaire from it. However, in recent years, his contributions have been increasingly celebrated. In addition to the Internet Hall of Fame induction, tech history enthusiasts often highlight that a Black Caribbean man was the one who invented the first internet search engine – a fact that surprises many who assume Google was the start of it all. Emtage’s story underscores that innovation can come from unexpected places and that the early internet was shaped by a diverse group of pioneers.
Archie as a Cultural Footnote: Archie and its contemporaries (Veronica, Jughead, etc.) are sometimes referenced in geek culture and nostalgia about the early net. While the average person today hasn’t heard of Archie, within the computing community it’s remembered as a trailblazer. In fact, until just recently, a legacy Archie server in Poland was still operational for historical and educational purposes. And there are hobbyists who have kept Archie running for fun – so if you’re curious, you can actually try out Archie searches via some modern web interfaces that hook into those old indexes. It’s a bit like using a rotary phone in the age of smartphones – a reminder of how things used to be.
Setting the Stage for Google (and Beyond): Ultimately, Archie’s greatest legacy is that every modern search engine stands on its shoulders. The evolution from Archie to Google to today’s AI-powered search assistants is a continuous line of progress. We went from searching file names, to searching text, to searching the semantic meaning of questions. But the seed of that idea – that we can query a vast network and instantly get information – was planted by Archie. The convenience we now enjoy daily owes a debt to that first search engine. In the grand timeline, Archie opened the door, and the likes of Google sprinted through it.
Conclusion
Archie may not be a household name today, but its impact on our digital world is undeniable. It was the little search engine that could – born from a graduate student’s frustration, running on the primitive internet infrastructure of its time, yet it managed to fundamentally change how we find information online. By introducing the world to the concept of an internet search engine, Archie paved the way for the likes of Yahoo!, Google, Bing, and every other search tool we rely on now.
From the late-night computer labs of McGill University in 1990 to the ubiquitous search bars of 2025, the evolution that started with Archie has revolutionized our relationship with knowledge. The next time you effortlessly search for something on your smartphone or ask a voice assistant a question, take a moment to appreciate that, not so long ago, none of this was possible. It took visionaries like Alan Emtage to make the leap. Archie, the first internet search engine, was a modest beginning that launched a digital revolution – one that truly changed everything about navigating the vast information landscape of the internet.




